AI 字幕(Whisper)
用 Whisper 本地识别给无字幕视频生成字幕,并可选 Google / Bing / AI 翻译;硬件要求、模型选择、参数详解与节流保护
当一段视频没有任何字幕(既没有内嵌轨道,也没有外挂文件)时,应用可以本地启动 Whisper 模型,对正在播放的音频做实时语音识别,把听到的话变成字幕。识别出的原文还可以再交给 Google / Bing / 你自己的 AI 服务做实时翻译,常见用途是:英语视频 → 中文字幕。
本章针对第一次配置的小白,按"先想清楚硬件 → 一次性配好设置 → 在播放器里随时切换"的顺序走完一遍。
一句话先讲清楚硬件
Whisper 是本地推理,吃的是你自己的电脑
所有识别工作都在你的设备上跑,不上云、不发音频到任何服务器。这意味着:
- GPU 是必需品:哪怕集显也比 CPU 快很多,独显(NVIDIA / AMD / Intel Arc)才是正常体验。
- CPU 几乎不可用:除非你只用最小的
tiny/base模型并且能容忍延迟很高、识别质量很差。中等以上模型用 CPU 跑,几十秒的音频要算几分钟,根本追不上播放。 - 显存(VRAM)决定能跑多大模型:4 GB 显存差不多到
medium,6 GB+ 才稳跑large-v3。
如果你的设备只有核显且较老(10 代 Intel 之前 / Vega 之前),现实地说:要么挂 外部字幕文件,要么换台机器。
全流程:5 步让 AI 字幕跑起来
下面这 5 步只需要做一次,之后所有视频都自动用同一套配置。
1. 下载一个 Whisper 模型
进入 设置 → 播放器设置 → Whisper 实时字幕,点最上方的「下载 Whisper 模型」按钮,会跳转到 Hugging Face 上的 ggerganov/whisper.cpp 仓库,把模型 .bin 文件保存到任意目录(例如 D:\Models\whisper)。
模型该选哪个?按显存挑:
| 模型 | 体积 | 显存占用(参考) | 识别质量 | 适用场景 |
|---|---|---|---|---|
tiny / base | 75 MB / 150 MB | < 1 GB | 较差 | 试用 / 仅英文 / 没独显的兜底 |
small | 480 MB | ~2 GB | 一般 | 集显或低端独显 |
medium | 1.5 GB | ~3-4 GB | 较好 | 主力推荐 |
large-v3 / large-v3-turbo | 1-3 GB | 5-7 GB | 最好 | 6 GB+ 独显,复杂语种首选 |
带 -q5_0 / -q8_0 后缀的是量化版,体积和显存更小、效果几乎不损失,优先选量化版。
不知道怎么选?
显存 ≥ 6 GB → 选 ggml-large-v3-turbo-q5_0.bin;4 GB → medium-q5_0;2 GB 或集显 → small-q5_0;其它情况老老实实从 base 起步。
2. 指定模型路径
在「模型文件路径」一行点「选择文件」,找到刚才下载的 .bin。这一步配置后会一直生效,重启应用也不用再选。
3. 选 GPU 后端(Vulkan / CUDA)
「GPU 后端」决定 Whisper 如何调用你的显卡:
- Vulkan(默认,推荐):兼容性最广,应用已经内置 Vulkan 后端,所有现代显卡(NVIDIA / AMD / Intel Arc / 集显)都能用,开箱即用,不需要任何额外安装。
- CUDA:仅 NVIDIA 显卡,性能略好于 Vulkan,但需要额外提供 CUDA 12 运行时文件夹(含
ggml-cuda.dll+cudart、cublas、cublasLt等)。设置项里的「下载 CUDA 运行时」按钮会带你到 Rodel.Player.Public 上的 cuda-runtime release,下载对应架构的压缩包解压到任意目录,再在「CUDA 运行时文件夹」一行选中该目录即可。
先 Vulkan 再说
新手直接用默认的 Vulkan 即可。等你确认 Whisper 能正常工作、又是 NVIDIA 卡、又对每秒处理量有更高要求,再考虑切到 CUDA。
4. 选识别语言和翻译目标
- 识别语言:选「自动检测」就行,Whisper 会从音频中自动判断语种。如果你已经知道音频是什么语言,显式指定会快一点也准一点。
- 翻译目标语言:你想最终看到的字幕语言。比如听英文播客、想看中文,就选「简体中文」。选「不翻译」就只显示识别原文,不做翻译。
5. 在视频里开 AI 字幕
打开任何一个没有字幕的视频,传输栏的「字幕」按钮里会出现 Whisper 入口,点一下即可开始识别。第一次启用时,模型会加载到显存,等几秒之后就能看到字幕一段一段冒出来了。
播放器内的字幕面板里也能临时改识别语言、翻译目标和翻译服务,不会影响你在设置里保存的默认值。
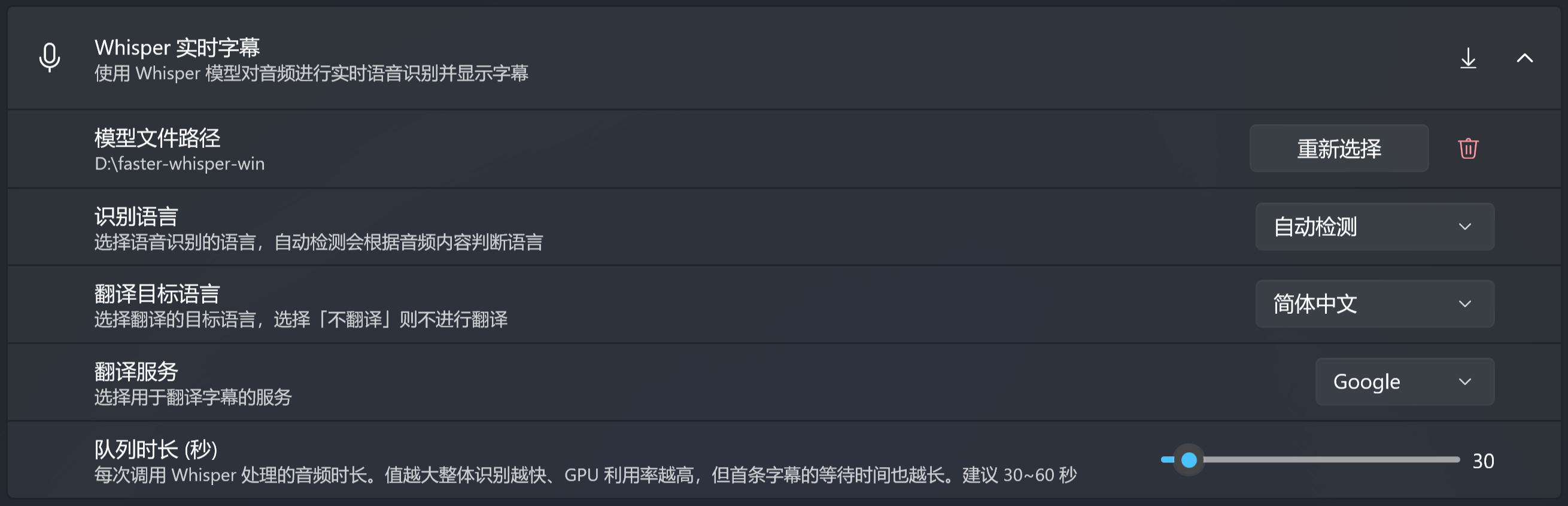
翻译服务详解
「翻译服务」决定了识别后的原文走哪条路被翻译成你的目标语言。三家都被同一套节流逻辑保护(见下文),但行为差别很大:
Google(默认,免费)
走 Google 翻译公开网页接口,免账号、免 API key。短期高频访问可能被 Google 临时拦截(错误率上升 / 暂时不可用),但只要节流默认开着就基本没事。
Bing(免费)
走必应翻译。和 Google 类似,免账号、免 API key。多数语种质量略低于 Google,但被风控的概率更低。
AI(OpenAI 兼容服务,本地首选)
把识别原文发给一个支持 OpenAI Chat Completions 协议的服务做翻译。这里强烈建议先考虑本地 LLM 框架,再考虑商业 API:
首推本地 LLM 框架(隐私友好、零费用、无速率限制):
- Ollama:最易上手,一行命令拉模型并启动 OpenAI 兼容服务(默认
http://localhost:11434/v1)。 - LM Studio:图形界面,启用「Local Server」后即提供 OpenAI 兼容端点。
- vLLM:高吞吐推理框架,适合有独显且想跑得更快的进阶用户。
模型选择建议优先专门的翻译模型,而非通用对话模型:
- TranslateGemma(Google 出品,基于 Gemma 3 专为翻译微调,提供 4B / 12B / 27B 三个尺寸)— 显存占用低、效果稳,强烈推荐。Ollama 用户可直接:
ollama run translategemma(参见 ollama.com/library/translategemma,可附:4b/:12b/:27b选择尺寸)。 - 通用模型(
qwen2.5、llama3.1、gemma3等 4B-8B 量化版)也能用,但更容易"自由发挥"出多余解释。
只有在本地资源不足、或者你有商业 API 的预算时再选 OpenAI / DeepSeek / Moonshot / 通义这类云端服务。
需要先在 设置 → 外部服务设置 → AI 服务 里把上述服务(云端或本地)添加好(Endpoint 例如 http://localhost:11434/v1,Key 留空或填占位字符串),回到 Whisper 设置后会出现:
- AI 服务:从你已经配置好的服务里选一个
- AI 模型:从该服务支持的模型里选一个
- Prompt 模板:留空使用内置默认模板,进阶用户可自定义。详见下一节。
选择云端 API 时注意成本
每出一段字幕就发一次请求,1 小时视频可以累计很多次。开下文「字幕翻译节流」可以显著抑制总量,并清楚自己 API 提供商的计费模型。用本地框架(Ollama 等)则没有这个问题,吃的是你自己的电力。
Prompt 模板详解
留空时使用内置默认模板,把识别原文翻译为目标语言,并把当前剧集元数据(系列名、分集名、剧情简介)作为背景上下文。默认模板(节选):
You are a professional subtitle translator.
Translate the user's sentence from {source_lang} to {target_lang}.
Context (do NOT re-translate, only use as background reference):
- Series: {series_title}
- Episode: {episode_title}
- Synopsis: {description}
Previous user/assistant messages in this conversation are PREVIOUS subtitle
lines and their translations, provided ONLY for terminology and tone
consistency. Do not continue them. Only translate the LATEST user message.
Rules:
1. Output ONLY the translated sentence — no quotes, no prefix like
"Translation:" or "译文:", no markdown, no explanation, no thinking.
2. Preserve speaker tone, formality and punctuation style of the source.
3. Keep proper nouns (names, places) consistent across lines.
4. If the source line is non-verbal (music, sound effects, on-screen text
tags), translate the meaning naturally; do not invent dialogue.支持的占位符(在你自定义模板时直接写进去即可):
| 占位符 | 含义 |
|---|---|
{source_lang} | 源语言代码(识别出的语种,未知时为 auto) |
{target_lang} | 目标语言代码(如 zh-Hans、en) |
{series_title} | 当前剧集 / 系列标题 |
{episode_title} | 当前分集标题 |
{description} | 剧情简介 |
任意元数据为空时,包含该占位符的整行会被自动剔除——不会出现"系列名:(空)"这种干扰模型的占位行。所以本地视频缺元数据时可以直接用默认模板,不会出问题。
什么时候要自定义?
- 不需要剧集背景:本地视频通常没有 series/episode/synopsis,模板里的
Context块会自动消失;如果你完全不想发这些字段,可以在自定义模板里把整段删掉。 - 风格偏好:例如想要更书面 / 更口语化 / 强制简体中文不掺繁体,加一行风格规则即可。
- 不需要严格的"只输出译文"约束:如果你用的是 TranslateGemma 这种"教得很到位"的翻译模型,规则部分可以精简到一两条,输出会更自然。
- 特定术语表:写一段术语映射("Frodo→佛罗多"),模型会优先采用。
修改建议:从默认模板复制一份,按需删行 / 改语气,保留至少一条"只输出译文"的规则——否则一些小模型会把"译文:xxx"也写进字幕。改完直接保存,下一段字幕翻译就会用新模板。
字幕翻译节流(成本与速率保护)
入口:设置 → 播放器设置 → Whisper 实时字幕 → 字幕翻译节流。
为什么要有这个:
- 视频 seek / 切轨 / 重连时,识别缓冲会一次吐出几分钟内容,无节流的话会一次发出几十次翻译请求。
- AI 翻译按调用次数 / token 计费,无节流会快速烧钱;Google / Bing 频率太高会被风控暂时拒绝服务。
开关打开后(默认开):
- 翻译窗口(秒):默认 60 秒。只翻译"播放点之后 N 秒内"的字幕。播放推进时再翻新冒出来的内容。值越小越省,太小(< 30)可能字幕来不及显示。
- Seek 防抖:拖进度条 1.5 秒内不发新翻译请求,等位置稳定再发,避免 seek 抖动连续触发。
- 重复 / 极短句过滤:whisper 的重复幻觉、纯标点等内容直接丢弃。
- 复用缓存:相同原文短时间内复用上一次翻译,不重复请求。
- 每分钟 / 每会话上限:硬上限兜底,触顶后暂停翻译,进度条状态会显示原因。
想看节流命中情况?
打开播放器 stats 覆盖层(按 I),按数字 5 切到「Whisper Translation」页(WinUI 模式下也可以点击顶部分段控件的 5),可以看到 HTTP 调用数、各种跳过计数和缓存使用情况。
后端可在 设置 → 播放器行为 → 「Stats 覆盖层后端」切换。HDR 屏幕推荐保留 WinUI 默认,避免 mpv 内置 OSD 引发 1Hz 亮度闪烁。
其它高级参数
队列时长(秒)
每次喂给 Whisper 的音频片段长度。默认 30 秒,可在 15–300 之间调:
- 越大:整体识别速度更快、GPU 利用率更高(一次喂的多 → 摊薄启动开销),但第一条字幕等待时间更久。
- 越小:首条字幕出来更快,但 GPU 反复启动效率下降。
新手保留默认即可。
启用 DTW 时间戳
默认关闭。开启后通过 cross-attention 对齐让每段字幕的时间戳更准(不会"提前 / 滞后整句"),代价:
- 强制关闭 flash attention,推理速度下降 25-40%;
- 不再跳过静音段,能耗上升。
只有当你发现字幕时间偏移明显、且机器吃得下 25-40% 性能损失时才打开。
在播放器里随时切换
视频播放中,传输栏「字幕」按钮里面除了切换内嵌轨、加载本地字幕外,还有 Whisper 区。在那里可以临时改:
- 识别语言(不喜欢自动检测时手动锁定)
- 翻译目标语言
- 翻译服务(AI / Google / Bing)
这些临时改动不会写回设置,下次播新视频还是用你的默认值。
常见问题
字幕迟迟不出?
- 看任务管理器的 GPU 占用,是 0% 就说明没正确用上 GPU——检查后端是否被切到 CUDA 但缺运行时;
- 模型选太大也会卡很久,先换
small/medium-q5_0试。
字幕出来了但识别得乱七八糟?
- 模型太小:升级到
medium起步; - 视频音轨噪声大:Whisper 对干净人声效果好,BGM 大或多人交谈本身就难;
- 识别语言被错猜:手动指定语言而不是「自动检测」。
AI 翻译很久不出 / 报错?
- 检查 AI 服务的 API key 余额;
- 节流开了的话,触顶时会暂停翻译,stats 覆盖层(按
I打开)的「Whisper Translation」页能看到原因。
想给一个视频关掉 Whisper?
- 字幕面板里切回内嵌轨道、加载本地字幕、或选「关闭字幕」——只要 Whisper 不再处于选中状态,识别就会停下。再次点 Whisper 入口又会重新启动。
隐私小提示
- Whisper 本地识别:音频不离开你的设备。
- Google / Bing 翻译:只把识别后的文本发给翻译服务(不发音频)。
- AI 翻译:把识别后的文本发给你配置的 OpenAI 兼容服务。
- 用本地框架(Ollama / LM Studio / vLLM):文本完全留在你电脑上,不出网络。
- 用云端 API(OpenAI / DeepSeek / 通义 等):受该服务自身的隐私政策约束。
如果你对发文本到云端有顾虑,最佳组合是:本地 Whisper 识别 + 本地 LLM(TranslateGemma)——全程不联网,效果还不差。或者干脆把翻译目标设为「不翻译」,只看识别原文。